Go 使用的 plan9 汇编语言初探
plan9 汇编既不同于 Intel-x86 家族的汇编,也不与 AT&T 标准相同,作者是 unix 操作系统的同一批人,bell 实验室所开发的,其实 plan9 是一个操作系统,我们主要关注构建它的汇编语言。
Go 语言早在 1.5 版本就实现了自举,即 使用 Go 语言去写 Go 语言。Go 的底层实现是使用 plan9 汇编完成的,并不是我们常见的 Intel 家族汇编,它与其他的汇编有几个不同点,在下文中一边比较一边介绍。
伪寄存器
plan9 抽象了 4 种伪寄存器:
- FP(Frame Pointer),帧指针,快速访问函数的参数和返回值。
- SP(Stack Pointer),栈指针,指向栈顶。
- SB(Static base pointer),静态基址,全局变量。
- PC(Program Counter),其实就是 IP(Instruction Pointer)的别名,指向下一条指令的地址。jmp等跳转指令还有分支控制等原理就是通过修改这个值。在 8086 机里等价于 CS:IP。
其实就是对 CPU 的重新抽象,这个抽象结构与具体的 CPU 结构无关。
它们之间的具体关系如下图:
与x86汇编的差异
许多人之前广泛了解的汇编可能是 AT&T 格式或者传统 Intel-x86 格式,AT&T 规范与 x86 有许多不同,而 plan9 与 AT&T 有许多相似的地方,比如操作数顺序许多是相同的,但 不完全等价。还是需要我们重新学习,这里列举一些常见区别。
Mnemonic | Go operands | AT&T operands
================================================
BOUNDW | m16&16, r16 | r16, m16&16
BOUNDL | m32&32, r32 | r32, m32&32
CMPB | AL, imm8 | imm8, AL
CMPW | AX, imm16 | imm16, AX
CMPL | EAX, imm32 | imm32, EAX
CMPQ | RAX, imm32 | imm32, RAX
CMPW | r/m16, imm16 | imm16, r/m16
CMPW | r/m16, imm8 | imm8, r/m16
CMPW | r/m16, r16 | r16, r/m16
CMPL | r/m32, imm32 | imm32, r/m32
CMPL | r/m32, imm8 | imm8, r/m32
CMPL | r/m32, r32 | r32, r/m32
CMPQ | r/m64, imm32 | imm32, r/m64
CMPQ | r/m64, imm8 | imm8, r/m64
CMPQ | r/m64, r64 | r64, r/m64
CMPB | r/m8, imm8 | imm8, r/m8
CMPB | r/m8, imm8 | imm8, r/m8
CMPB | r/m8, r8 | r8, r/m8
CMPB | r/m8, r8 | r8, r/m8
CMPW | r16, r/m16 | r/m16, r16
CMPL | r32, r/m32 | r/m32, r32
CMPQ | r64, r/m64 | r/m64, r64
CMPB | r8, r/m8 | r/m8, r8
CMPB | r8, r/m8 | r/m8, r8
CMPPD | imm8, xmm1, xmm2/m128 | imm8, xmm2/m128, xmm1
CMPPS | imm8, xmm1, xmm2/m128 | imm8, xmm2/m128, xmm1
CMPSD | imm8, xmm1, xmm2/m64 | imm8, xmm2/m64, xmm1
CMPSS | imm8, xmm1, xmm2/m32 | imm8, xmm2/m32, xmm1
ENTER | 0, imm16 | imm16, 0
ENTER | 1, imm16 | imm16, 1
操作数顺序不同
在 x86 中,一些常见指令是这样的:
MOV EAX, 10 ;EAX=10
MOV AH, [BL] ;AH=*BL
而在 plan9 中操作数的顺序会相反:
MOVL a+0(FP), AX ;AX=a
MOVB BX, AX ;AX=BX
不止这些,还有 LEA ADD SUB IMUL等等也都满足。
操作数大小表示法不同
在 x86 中,表示大小通过直接区分操作数,比如 AX 寄存器的高 8 位就是 AH ,低 8 位就叫 AL.。而 plan9 中通过不同操作码来区分:
MOVB $0x10, AX ;1B, Byte
MOVW $-10, DI ;2B, 1Word=2Byte
MOVL $0, SP ;4B, Double Word
MOVQ $1, DX ;8B, Quatury Word
寄存器
寄存器分为 实寄存器(real register)和 伪寄存器(pseudo register) ,前者在 CPU 内部,属于 CPU 的固件,作为与 CPU 直接产生信息交换的单位,具体种类与架构有关,可以通过 dlv 工具查看:
示例程序的机器为 AMD64,也就是 x86-64。不同的机器可能会因为 CPU 的不同而不同。
(dlv) regs
Rip = 0x00007ff90ed00771
Rsp = 0x000000cfd45ff260
Rax = 0x0000000000000000
Rbx = 0x0000000000000010
Rcx = 0x00007ff90eccd2c4
Rdx = 0x0000000000000000
Rsi = 0x00007ff90ed61a80
Rdi = 0x000000cfd4237000
Rbp = 0x0000000000000000
R8 = 0x000000cfd45ff258
R9 = 0x0000000000000000
R10 = 0x0000000000000000
R11 = 0x0000000000000246
R12 = 0x0000000000000040
R13 = 0x0000000000000000
R14 = 0x00007ff90ed548f0
R15 = 0x00000254e7900000
Rflags = 0x0000000000000246 [PF ZF IF IOPL=0]
Cs = 0x0000000000000033
Fs = 0x0000000000000053
Gs = 0x000000000000002b
后者是应用层抽象出来的概念,实际并不存在,目的是为了更方便地写汇编。
由于历史原因,x86 平台要保证向后兼容,要求在 64 位机上要能够运行 32、16、8位程序。解决方法是通过给寄存器加前缀实现的。
AH/AL -> AX -> EAX -> RAX
8 16 32 64
除此之外,还有这些对应关系
| X64 | rax | rbx | rcx | rdx | rdi | rsi | rbp | rsp | r8 | r9 | r10 | r11 | r12 | r13 | r14 | rip |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
伪寄存器
为了方便编程,plan9 还引入了 4 个伪寄存器,SP FP SB PC。想当年面试的时候(其实就是去年,我张口就来引入这四个是为了增加性能(猜的,回头想想还真是离谱。
这 4 个有不同的作用,其中 伪SP寄存器 还与 真SP寄存器 重名了,就更容易让初学者懵逼了,这里放个曹大的图就明白了。
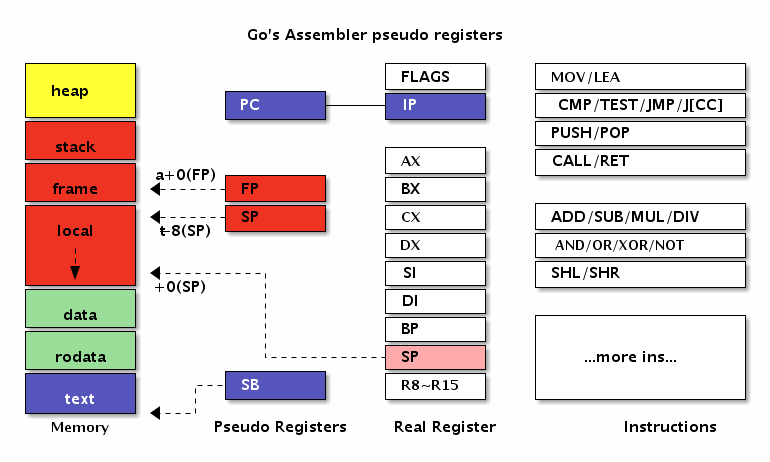
这个图里有一点歧义,红色部分是栈,黄色是堆,图中的关系是堆在上面,而实际堆是向上增长的。
另外还有一点,这张图里没有标明 实寄存器BP 的位置,BP 是栈基地址。
函数调用
这里拿一个简单的函数嵌套调用代码,来举例说明它们之间的具体位置关系和实现原理:
func upper() {
r0, r1 := f0(arg0, arg1)
}
func f0(arg0, arg1 int) (ret0, ret1 int) {
r0 := arg0 - arg1
r1 := arg0 + arg1
r1 = f1(r0)
return r0, r1
}
func f1(arg0 int) (ret0 int) {
return 1 + arg0
}
栈帧
函数实现嵌套调用依靠的数据结构就是栈,上面这个程序它的调用栈帧如下:
+------------+ <----------+
| .... | |
+------------+ |
| Ret1 | |
+------------+ |
| Ret0 |
+------------+ upper call stack
| Arg1 |
+------------+ |
| Arg0 | |
+------------+ |
| Ret Addr | |
+------------+ <----------+
real BP(pseudo SP) | upper BP | |
------------------> +------------+ |
| Local0 | |
+------------+ |
real SP | Local1 |
----------------> +------------+
| | f0 stack frame
|unused space|
| |
+------------+ |
| Ret0 | |
+------------+ |
pseudo FP | Arg1 | |
----------------> +------------+ |
| Ret Addr | |
+------------+ <----------+
|Caller f0'BP|
+------------+
| Local0 |
+------------+
| Local1 |
+------------+
| ... |
+------------+
验证
我们使用 FP/real SP/pseudo SP 来验证一下上面的栈帧示意图:
分析一个简单的程序
好了,终于见到 「真的汇编代码」 了,理论知识差不多了(误
package main
func add(x, y int) (sum int, sub int) {
z := x + y
w := x - y
return z, w
}
func main() {
c, d := add(2, 3)
}
前置知识
在命令行中执行 go tool compile -S -N -l main.go 查看汇编代码。看之前需要注意两点,
- 不管使用
go tool compile -S还是go tool objdump来查看汇编代码,都是和实际我们手写 plan9 不同的,不能照搬语法。这两者关于汇编指令的输出也是不同的。当然,十六进制肯定是相同的。 - 输出的所有 SP 指针无论带不带 symbol 都是实寄存器,而实际上在手写 plan9 时,如果使用了形如
symbol+offset(SP)的表达则指使用的是 伪SP指针,不带则是 真SP指针。 - 而实际手写在使用
FP寄存器时如果不带symbol会直接报错。
变量与常量
函数
"".add STEXT nosplit size=19 args=0x18 locals=0x0 funcid=0x0
0x0000 00000 (notify.go:7) TEXT "".add(SB), NOSPLIT|ABIInternal, $0-24
0x0000 00000 (notify.go:7) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (notify.go:7) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (notify.go:8) MOVQ "".b+16(SP), AX
0x0005 00005 (notify.go:8) MOVQ "".a+8(SP), CX
0x000a 00010 (notify.go:8) ADDQ CX, AX
0x000d 00013 (notify.go:8) MOVQ AX, "".~r2+24(SP)
0x0012 00018 (notify.go:8) RET
先看第一行内容:
"".add STEXT nosplit size=19 args=0x18 locals=0x0 funcid=0x0
内容虽然多,但是非常好理解,不同数值均给出了名称,但是更标准的表示法一般是这样:
TEXT runtime∕internal∕atomic·Cas(SB),NOSPLIT,$0-17
双引号里和 runtime/internal/atomic 都是函数名,可以省略,后面紧跟函数名。TEXT 是区段名。SB 是基于伪寄存器 SB 进行偏移,比如:
+4(SB)
a+8(SB)
一个是在 SB 寄存器起始地址上正向偏移 4 个字节,一个是从 SB 的 a 变量开始偏移 4 个字节。
由于 Go 语言函数的调用栈帧默认是动态伸缩的,初始大小只有 2KB,你可以使用 指令 来控制这个行为:
//go:nosplit
func str2slc(s string) []byte {
...
}
这条指令可以禁止扩容检测,这样做一定程度上可以增加效率。而汇编代码里的 nosplit 是编译器帮我们做的优化。除此之外,还有 WRAPPER、noinline 等许多指令,都是用来指导编译器的工作,例如禁用内联,禁止逃逸,禁止逃逸分析等等,具体及更多信息可以在官方文档 golang.org/cmd/compile 查看。
$0-17 的 0 是函数栈帧大小,指函数内的局部变量总大小,这个值包括准备子函数参数的开销。17 是参数大小,'-' 不是减号,只是连接符,不要想当然认为栈向下增长所以是做减法(不过好像问题也不大
需要注意的是,如果没有 nosplit,则必须给出参数大小,而不能直接 $x,因为 Go 语言编译器已无法根据函数签名进行占用空间大小的推导。
所以,最终定义函数的标准语法如下:
TEXT symbol(SB), [flags,] $framesize[-argsize]
手写来练习一下吧
看了这么多,来手写一个简单的 plan9 汇编程序练习一下。
目标:实现一个求整型切片元素和的函数,函数签名为:func addSliceInt(slc []int) int。举个例子,如果 slc := []{1,2,3,4},那么返回 10.
总结
plan9 是一个操作系统,对应一套汇编语法,被称为 plan9 汇编,与 AT&T 规范非常相似,也不完全一样。与传统 x86 汇编差异较大。
plan9 重新定义了 4 个伪寄存器来方便编程,函数嵌套调用的核心就是依靠栈的先进先出特性,在调用前来保护 Caller 的执行现场,并在 Callee 执行完返回后恢复现场,从而继续执行。
- 没有 push,pop 等栈操作,栈的增缩是通过对 sp 栈顶寄存器的加减实现的,例如 +8(sp)
- 操作数的大小不是通过区分操作码来实现的,而是通过操作码的后缀实现,例如复制
ax寄存器低 1 字节到第二字节,在x86汇编中是通过mov ah,al,而在 plan9 中则是通过movb al,ah- b w d q分别代表1 2 4 8 Byte,含义是byte,word,double word,quatury。
- 操作数在第一个参数,结果放在第二个参数,与intel汇编相反,具体看第二条
我们学习 plan9 汇编其实也并没有太大困难,前期在学习时也未必要看懂全部的汇编代码,可先学习大概思路,再深入了解即可。
但是为什么 plan9 不与 x86 系兼容呢,而要单独开发一套自己的语法呢,我看了不少人的解释,貌似是因为 unix 团队是学院派,特立独行,也不屑于商业化(就是玩
